How do I generate the movies's page?
<2025-08-16 Sat>
The section movies of my web page has reached out 700 movies. So… it is a perfect moment to show how I generate it.
First version
For the record, the first version was totally manual. I used the data provided by LetterBoxd, as you can see on the image below. I edited the CSV with a python script to get the org table then I uploaded it to here. A manual copy&paste.
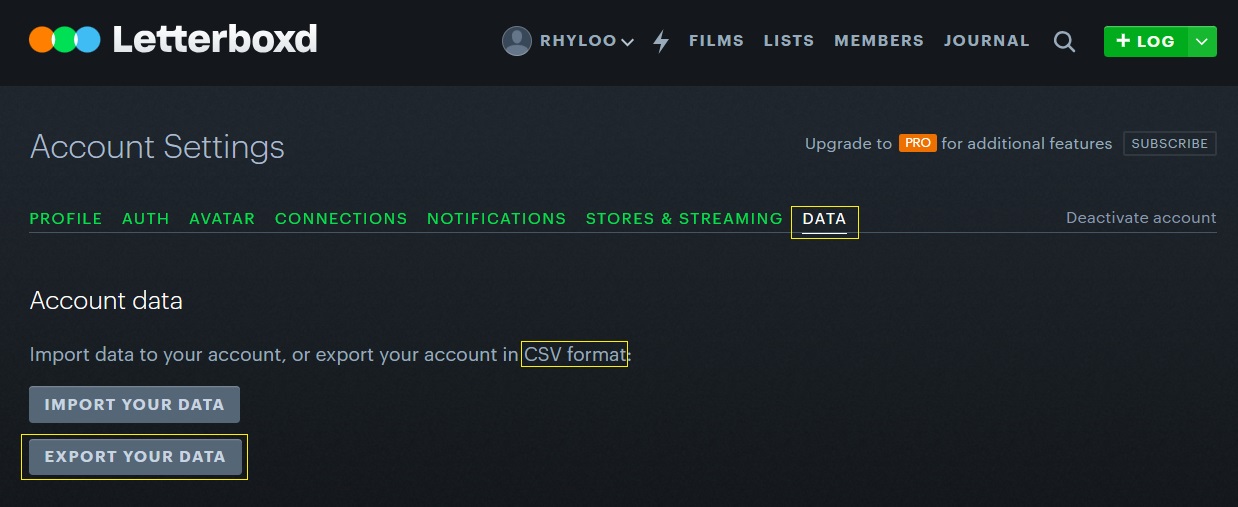
It was an effective way of achieving my initial goal, but to be honest, I didn't like it. You and my engineer's mind know that this process must be automated.
NOTE: I don't have the script :c
Second version
The new version is a fully automated Python script that is run by a cron job (for more information check /etc/cron.d/website).
The next code was written with IA (ChatGPT). I shared with ChatGPT my first version and some tweaks I wanted, then I edited to achieve what I want.
What is about the API?
LetterBoxd doesn't offer a free or paid API for personal projects, so I wrote a simple scraper to retrieve my movie history, minimising the number of requests to avoid bans or increased server loads.
The code
Here are the libraries I use for the scrapper.
import re # Regular expressions for pattern matching and text processing import os # Operating system interface (file paths, environment, etc.) import time # Time-related functions (sleep, timestamps, etc.) import requests # HTTP requests to interact with web resources import fileinput # Read or modify files line by line from bs4 import BeautifulSoup # HTML/XML parsing and web scraping from datetime import datetime # Date and time manipulation
I defined five variables:
- base_url: This defines the URL where the script will search for movies.
- last_movie_url: This defines the URL to retrieve the date on which a movie was watched.
- output_file: This variable defines a temporary file called 'movies_list.txt'.
- status: The script sometimes stops working because Letterboxd updates their page, changing class names and IDs. I use this variable "to send" a notification.
base_url = "https://letterboxd.com/rhyloo/films/by/date/page/" last_movie_url = "https://letterboxd.com/rhyloo/films/diary/" output_file = "/tmp/movies_list.txt" status = True
get_movie_names is the core of the scraper. It looks for the <li> tag and the griditem class to find the movies. As I said, it usually fails on the class name because Letterboxd changes it (this has happened to me at least three times). I clean the names to remove any strange characters, too.
def clean_name(name): """Remove unwanted characters from a movie name, keeping punctuation like :,.?!"-""" return re.sub(r'[^\w\s:,.?!"-]', '', name).strip() def get_movie_names(page_url): """Fetch movie names from a page and return a list of cleaned titles.""" try: status = True response = requests.get(page_url) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') # Buscar contenedores de pósters poster_containers = soup.find_all('li', class_='griditem') movie_names = [] for container in poster_containers: img_tag = container.find('img') if img_tag and img_tag.get('alt'): movie_names.append(clean_name(img_tag['alt'])) return movie_names except Exception as e: status = False return []
Here are some more auxiliary functions. get_last_date_movie simply retrieves the date on which I last watched a movie, while write_to_file saves new movies to a file. Finally, split_into_row creates a list of lists fixed to three.
def get_last_date_movie(): """ Fetch the date of the last movie from a webpage. Returns: str: The date in format 'DD-MM-YYYY' if found. "Opsss!": If the date element is missing. None: If an error occurs (e.g., network issue, invalid HTML). """ try: response = requests.get(last_movie_url) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') date_link = soup.find(class_='daydate') if date_link: date_link = re.search(r'(\d{4}).(\d{2}).(\d{2})', str(date_link)) year = date_link.group(1) month = date_link.group(2) day = date_link.group(3) last_movie = day + '-' + month + '-' + year return last_movie else: return "Opsss!" except Exception as e: return None def write_to_file(file_path, movie_names): """ Write movie names to a file. - If the file exists and is not empty, replace its first line with new movie names. - If it doesn't exist or is empty, create it and write all names. """ if os.path.exists(file_path) and os.path.getsize(file_path) > 0: # Edit the existing file in-place (replace the first line with new movies) with fileinput.input(file_path, inplace=1) as f: for xline in f: if fileinput.isfirstline(): for element in movie_names: print(element) else: print(xline.strip('\r\n')) else: # Create a new file and write movie names line by line with open(file_path, 'w', encoding='utf-8') as file: for name in movie_names: file.write(name + '\n') def split_into_rows(movies): """ Divide a list of movies into rows of a fixed number of columns (default 3 per row). """ rows = [] while movies: row = movies[:3] rows.append(row) movies = movies[3:] return rows
This is where the main part of the script starts. It takes the last movie saved in the movies_list.txt file. With a loop, it iterates over each page and checks if the last movie saved in the file is already in the new movies list. If so, it stops.
# MAIN if os.path.exists(output_file): with open(output_file, 'r', encoding='utf-8') as myfile: first_line = myfile.readline() else: first_line = "" page_number = 1 all_movie_names = [] while True: page_url = base_url + str(page_number) + "/" movie_names = get_movie_names(page_url) if not movie_names: break all_movie_names.extend(movie_names) if first_line.strip('\n') in all_movie_names: target_index = all_movie_names.index(first_line.strip('\n')) all_movie_names = all_movie_names[:target_index+1] break page_number += 1 time.sleep(30) write_to_file(output_file, all_movie_names)
Finally I create an .org file, which is exported to HTML using org-publish.
chars_to_be_delated = ' ' with open(output_file, 'r') as myfile: contenido = myfile.read() contenido_filtrado = ''.join(c for c in contenido if c not in chars_to_be_delated) with open(output_file, 'w') as myfile_filtered: myfile_filtered.write(contenido_filtrado) actual_date = datetime.now().strftime("%Y-%m-%d %a") with open(output_file, 'r', encoding='utf-8') as myfile: movies = [linea.strip() for linea in myfile.readlines()] max_movie = len(movies) num_digits = len(str(max_movie)) movies_size_column = f"{num_digits}em" rows = split_into_rows(movies) last_movie_date = get_last_date_movie() if status: html_status = f"@@html:<div class=\"warning\">✅ The script is working.</div>@@" else: html_status = f"@@html:<div class=\"warning\">⚠️ The script is not working.</div>@@" org_mode = f"""#+TITLE: MOVIES #+author: J. L. Benavides #+date: <{actual_date}> #+last_modified: [{actual_date}] #+DESCRIPTION: Personal blog - Jorge Benavides Macías - Watched movies #+OPTIONS: toc:nil num:nil ^:nil I am a film lover, I really enjoy watching films very much. It's a hobby I can do alone or with others. Actually I have watched more than {max_movie-max_movie%100} films, below is the full list since I started registering them on [[https://letterboxd.com/][letterboxd]].\n\nI used to update this content [[file:how-do-i-get-movies-draft.org][manually]], but now it is [[file:how-do-i-get-movies-draft.org][automatic]], so it's always up to date.\n\nBy the way my user is [[https://letterboxd.com/rhyloo/films/by/date/][Rhyloo]]. {html_status} @@html:<div class="last-update">Last update: {actual_date}</div>@@ @@html:<div class="last-update">Total movies watched: {max_movie}</div>@@ @@html:<div class="last-update">Date last movie: {last_movie_date}</div>@@ #+ATTR_HTML: :class table-movies :style "grid-template-columns: {movies_size_column} 1fr;" | <c> | <c> | <c> | <c> | <c> | <c> | | No. | Movie Name | No. | Movie Name | No. | Movie Name | |-----+--------------------------------------------------------+-----+----------------------------------------------------------------------+-----+-------------------------------------------------------------------------------------| """ number = 1 for row in rows: row.extend([''] * (3 - len(row))) org_mode += f"| {number:<3} | {row[0]:<50} |" if row[1]: org_mode += f" {number+1:<3} | {row[1]:<68} |" else: org_mode += f" | |" if row[2]: org_mode += f" {number+2:<3} | {row[2]:<80} |\n" else: org_mode += f" | |\n" number += 3 with open(output_org, 'w', encoding='utf-8') as myfile_org: myfile_org.write(org_mode)
Final thoughts
I'm not particularly proud of this code. I didn't write it entirely, so it's a mess, like the famous spaghetti code. I could simplify it, or at least clean up the code to make it more readable.
Maybe I can remove the functions… in this code they are not necessary because I don't reuse them. Something sequential like:
- Step ONE: Get data
- Step TWO: Save data
Also, I find Python a bit of a headache. The code never feels clean to me; it's just a bunch of lines into one file with un konwn libraries. I prefer C.
Ghostbusters/Transcript Modified
Are you troubled by strange noises in the middle of the night?
Do you experience feelings of dread in your basement or attic?
Have you or any of your family ever seen a spook, specter or ghost?
If the answer is yes, then don't wait another minute. Pick up your phone and call the professionals.
Contact at me at rhyloo dot com!